Querying json datasets with jq
Working with JSON datasets is really common task nowadays, almost any API will output information on this format, but is still complex to manipulate this format when compared with plain-text combined with common unix commands like cut, awk, sed, etc.
To reduce this gap jq was developed with exactly this paradigm in mind jq is like sed for JSON data. This post will walk through the details to: select fields (projection), flatten arrays, filter jsons based on a field value and convert JSON to CSV/TSV.
#
Installing jq
jq
I’m using homebrew to install jq, so you just need to use:
$ brew install jq
Also you can download binaries for your platform or you can also play online jqplay.org
#
Sample Data
As sample data, I will use a few tweets I get from my timeline, those jsons are obtained using the Twitter API statuses/lookup.json.
The dataset I’m using for the sample statuses.jaon
#
Pretty Print
Opening a json file with cat or less makes really hard to understand its content, even more if the file is compacted, as most the API does. It would looks like this:
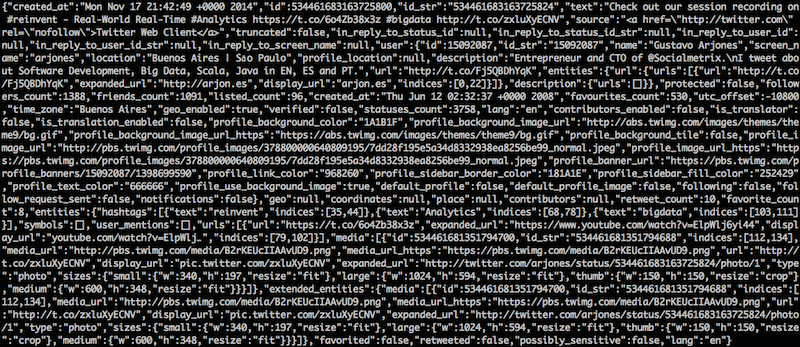
Just by passing the entire file to jq, we can have a much better view of file’s content, display first 3 lines of json:
$ head -3 statuses.json | jq '.'
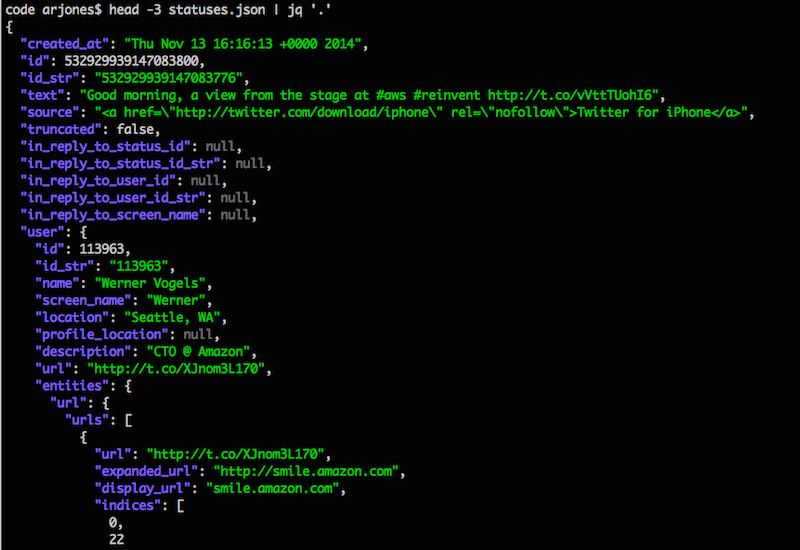
Now it is very clear simple to identify the json structure and work with its fields.
#
Select Fields (Projection)
Now we can select some fields from the json, I’m interested to have the Twitter User and the Number of Followers:
$ cat statuses.json | jq '.user.name, .user.followers_count'
"Werner Vogels"
63936
"Pablo H. Paladino"
1116
"Gustavo Arjones"
1388
"Gustavo Arjones"
1388
"Gustavo Arjones"
1388
This output is not that useful, I prefer to create a new json with the information I need:
$ cat statuses.json | jq '{name:.user.name, followers:.user.followers_count}'
{
"name": "Werner Vogels",
"followers": 63936
}
{
"name": "Pablo H. Paladino",
"followers": 1116
}
{
"name": "Gustavo Arjones",
"followers": 1388
}
{
"name": "Gustavo Arjones",
"followers": 1388
}
{
"name": "Gustavo Arjones",
"followers": 1388
}
Using the jq switcher -c you can have one-liner json, that can be useful to input for another process:
$ cat statuses.json | jq -c '{date:.created_at, screen_name:.user.screen_name, followers:.user.followers_count}'
{"date":"Thu Nov 13 16:16:13 +0000 2014","screen_name":"Werner","followers":63936}
{"date":"Fri Nov 14 14:53:18 +0000 2014","screen_name":"palamago","followers":1116}
{"date":"Thu Nov 13 22:36:01 +0000 2014","screen_name":"arjones","followers":1388}
{"date":"Mon Nov 17 21:42:49 +0000 2014","screen_name":"arjones","followers":1388}
{"date":"Thu Nov 13 23:48:23 +0000 2014","screen_name":"arjones","followers":1388}
#
Flatten Arrays
Sometimes the content we’re looking for is inside an array, it is really easy to parse this. As an example, we will list all urls inside tweets:
$ cat statuses.json | jq -r '.entities.urls[].expanded_url'
http://on.wsj.com/1sJlEEp
https://www.youtube.com/watch?v=ElpWlj6yi44
Or the images attached:
$ cat statuses.json | jq -r '.entities.media[].media_url_https'
https://pbs.twimg.com/media/B2VY877IUAI1wKn.jpg
https://pbs.twimg.com/media/B2aJ8P6CcAAkgti.png
jq: error: Cannot iterate over null
https://pbs.twimg.com/media/B2rKEUcIIAAvUD9.png
jq: error: Cannot iterate over null
When I tried to do the parse .entities.media[] field I got some errors, it happened because not all tweets contains the field media, to avoid the error message we need to filter out fields with null vales
#
Filter json based on a field value
json based on a field value
With the command select we’re able to remove the jsons that doesn’t contains .entities.media element: select(.media != null)
$ cat statuses.json | jq -r '.entities | select(.media != null) | .media[].media_url_https'
https://pbs.twimg.com/media/B2VY877IUAI1wKn.jpg
https://pbs.twimg.com/media/B2aJ8P6CcAAkgti.png
https://pbs.twimg.com/media/B2rKEUcIIAAvUD9.png
#
Everything together
This example selects only tweets made by me (user.screen_name == "arjones") and project the count of ReTweets, Favorites for each tweet:[]
$ cat statuses.json | jq -c '. | select(.user.screen_name == "arjones") | {rt:.retweet_count, fav:.favorite_count, id:.id, date:.created_at}'
{"rt":1,"fav":3,"id":533025519244025860,"date":"Thu Nov 13 22:36:01 +0000 2014"}
{"rt":10,"fav":8,"id":534461683163725800,"date":"Mon Nov 17 21:42:49 +0000 2014"}
{"rt":0,"fav":0,"id":533043730668736500,"date":"Thu Nov 13 23:48:23 +0000 2014"}
#
Convert JSON to CSV/TSV
There is a very long discussion on github to support CSV/TSV output
My preferred trick to make it work is to convert the fields to an array and use the | @csv command.
This example outputs the same content as above but in CSV format:
$ cat statuses.json | jq -r '. | [.retweet_count, .favorite_count, .id, .created_at] | @csv'
59,46,532929939147083800,"Thu Nov 13 16:16:13 +0000 2014"
3,2,533271461533057000,"Fri Nov 14 14:53:18 +0000 2014"
1,3,533025519244025860,"Thu Nov 13 22:36:01 +0000 2014"
10,8,534461683163725800,"Mon Nov 17 21:42:49 +0000 2014"
0,0,533043730668736500,"Thu Nov 13 23:48:23 +0000 2014"
Once you have a CSV you can check these posts that can create an exploratory pipeline: