Processing Twitter’s top stories with Apache Spark (part 1)
Since I got to know News.me it surprises me with its simplicity and yet power to recommend me the best stories to read. I always thought it would be fun try to build something similar. So I decided to create a PoC of Twitter’s top stories using Apache Spark.
DISCLAIMER: this is a PoC, mainly focused on learning Spark, this architecture doesn’t represent a production level product neither I consider recommending stories for only one user as a big data problem.
#
TL;DR;
The code is available at Github, just create a valid Twitter API credentials and you can run it.
#
Solution
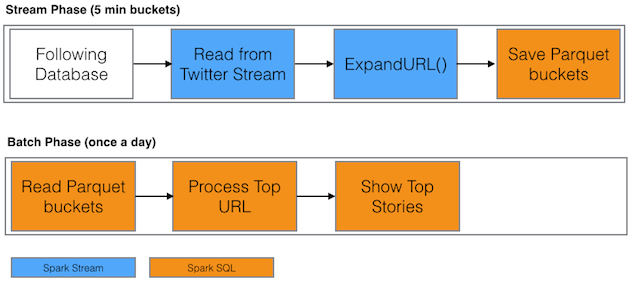
The solution is based on two stages:
-
Collect tweets from the stream, analize them and store those tweets whthat contains a link, expanding the link to its final destination (removing shortening and click counters)
-
Run a batch job to process the data from previous stage and create a top 10 list
#
Building & Running
I use Eclipse + Scala and typesafe plugin sbteclipse to create an Eclipse project.
$ git clone [email protected]:arjones/spark-news.git
$ cd spark-news
Now edit src/main/resources/twitter4j.properties.template adding your credentials and rename it to src/main/resources/twitter4j.properties:
twitter4j.oauth.consumerKey= //
twitter4j.oauth.consumerSecret= //
twitter4j.oauth.accessToken= //
twitter4j.oauth.accessTokenSecret= //
Let’s build our project:
$ sbt/sbt
> eclipse with-source=true
> assembly
> exit
And run it:
$ spark-submit \
--class io.smx.spark.news.CollectLinksFromStreamDrive \
target/scala-2.10/SparkNews-assembly-0.1-SNAPSHOT.jar \
following.txt
Edit following.txt adding accounts that you find interesting!
If everything is working properly, each 5 minutes you going to see a new folders at ./urls/999999999/ the numbers represent the unix timestamp, rounded down to minute. For example:
urls/1404627900/ --> 7/5/2014 11:25:00 PM GMT-7
You can check the activity, using Spark UI
#
Internals
Setup a StreamingContext with a 5 minutes window, load the accounts and create the Twitter Stream
// Setup the Streaming Context
val ssc = new StreamingContext(new SparkConf(), Seconds(300))
val tweets = TwitterUtils.createStream(ssc, None, followingList)
For each Tweet that contains a URL, extract it and if there are more than one url, extracts only the first:
// Consider only 1st URL on the Tweet
val url = URLExpander.expandUrl(status.getURLEntities.head.getExpandedURL)
Use SparkSQL to implicit convert a RDD[TweetContent] into a Schema RDD:
val sqlContext = new org.apache.spark.sql.SQLContext(ssc.sparkContext)
import sqlContext._
So we can go through each SchemaRDD and saveAsParquet to disk
urlsDStream.foreach { schemaRDD =>
...
...
...
links.saveAsParquetFile("urls/" + folderTimestamp) + ".parquet"
}
#
What’s next?
Leave this code running for a few hours so we have data for the next part, which involves calculating the best stories!