Spark Summit 2014 - Day 1
My personal notes during Spark Summit 2014.
![]()
#
Matei Zaharia (CTO, Databricks)
- More than 1000 attendees to the Summit! Very fast community growth.
- The most active big data project!
- Some stats from ohloh
- New features that came in last months: security, monitoring, HA
##
Spark SQL
- Query common DS directly from Spark
- From JSON!!! On Spark 1.0.1
- Uniform access from different Datasources
##
Machine Learning Library (MLlib)
- 40 contributors since Sep'13
##
Java 8 Support
##
Vision for Spark
-
Unified Platform for Big Data (Uniform API for diverse workloads over diverse storage and runtime)

-
Standard Library for Big Data
#
Ion Stoica (CEO, Databricks)
-
All major distributions supports Spark
-
SAP was announced as Spark Partner
-
Sparks Apps Certification Program (free, scripts are open-source)
-
Sparks Distro Certification Program (free)
-
Traditional Big Data pipeline

-
Databricks Cloud launched (Runs on AWS)

-
Workspaces:
- Notebooks
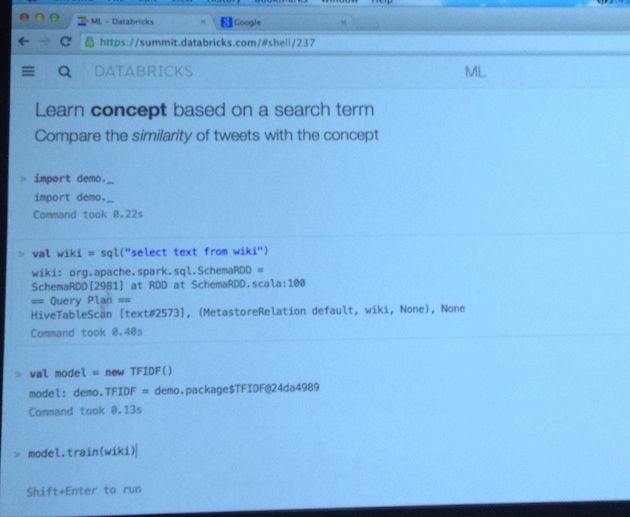
- Dashboards
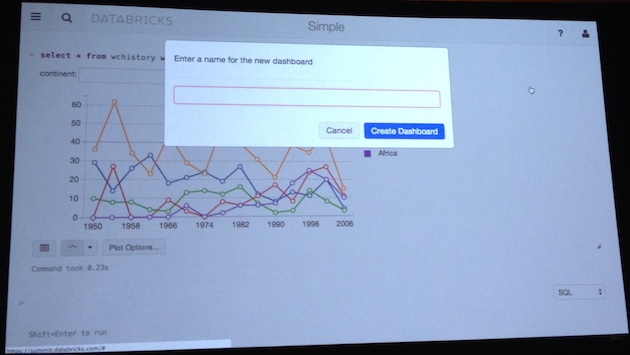
- Job Pipeline
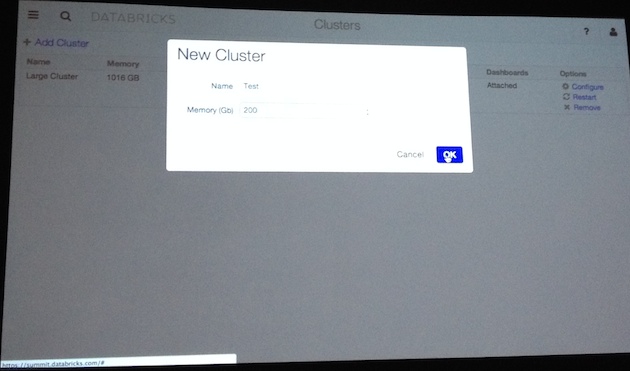
- Notebooks
Databricks Cloud Platform was really amazing on the demo. Wondering how much it can cost.
#
What’s Next for BDAS?
Mike Franklin (Director, UC Berkeley AMPLab)
About the Bad-ass stack bets:

Spark is just part of what we do!
Snapshot what they’re doing now:

##
What about updates?
Big Data Analytics assume Append-mostly data Working on that for ML
#
Spark and Cassandra
Martin Van Ryswyk (EVP of Engineering, DataStax)
Weather Channel uses Cassandra and Spark
Using Spark to feedback information to Cassandra, WITHOUT using ETL that’s reason
Driver Cassandra 1.0 ready. Not yet for Spark 1.0 coming soon. Sample code: 
#
Spark and the future of big data applications
Eric Baldeschwieler (Tech Advisor) @jeric14
- Real progress on community, people adoption and filing bugs.
- People taking Hadoop ETL and porting to Spark
Things to improve Spark:
- R bindings are necessary
- SparkSQL needs to be extended to run against more data stores, including object stores.
Lambda Architecture equivalent at Yahoo!
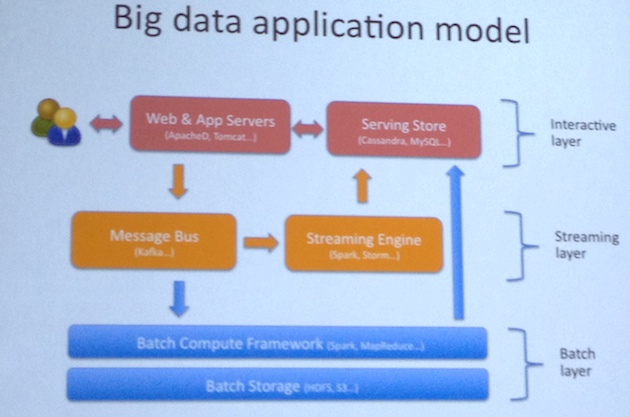
Tachyon can improve a lot Spark ecosystem.
“IMHO, Spark is the most exciting thing on Big Data today”
#
How to get start on Spark
A cool recommendation how to get start:
.@hhiranan I recommend this for a quick cluster: https://t.co/wo5RqyvJj3 @docker #sparksummit
— Oliver Vagner (@Oliver_Vagner) June 30, 2014
#
Spark meets Genomics: Helping Fight the Big C with the Big D
David Patterson (AMP Lab, UC Berkeley)
Emotional story on Spark Summit: SNAP Helps Save A Life
How to get involved? BD Genomics