Spark Summit 2014 - Day 1 (Afternoon)
Following the Spark Summit 2014 - Afternoon talks notes
#
Performing Advanced Analytics on Relational Data with Spark SQL
Michael Armbrust (Databricks) Slides
-
Shark - uses hive optimizer which wasn’t designed to Spark Ending active development of Shark!
-
SchemaRDD <–> RDD provides an unified abstraction to work.

-
SchemaRDD using Scala supports nested Case Class to define tables!
-
You can leverage on the Hive efforts due to wrappers and translators
-
Spark SQL relies on Scala Reflection to improve performance
-
Spark SQL is many times faster Shark
##
Demo:


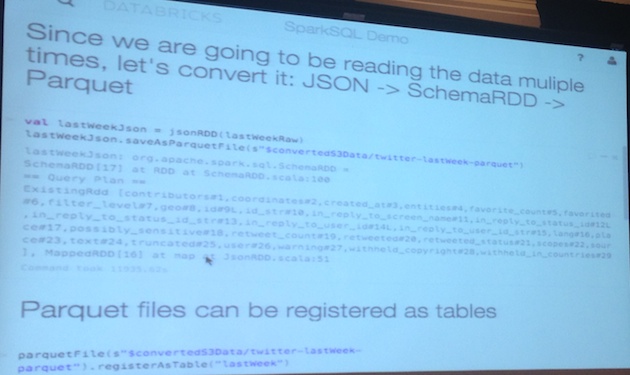
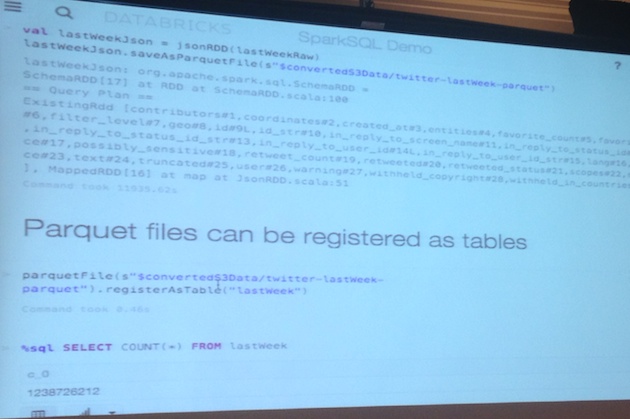
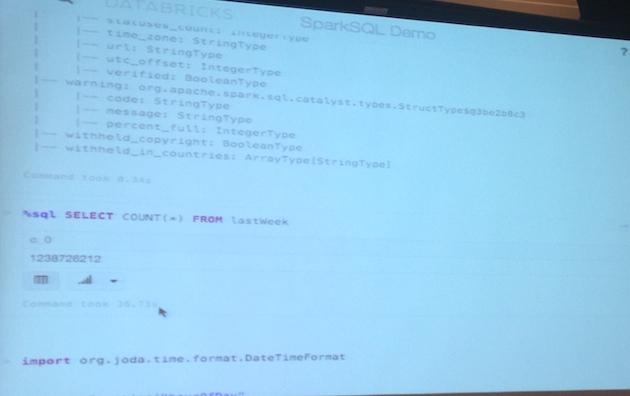


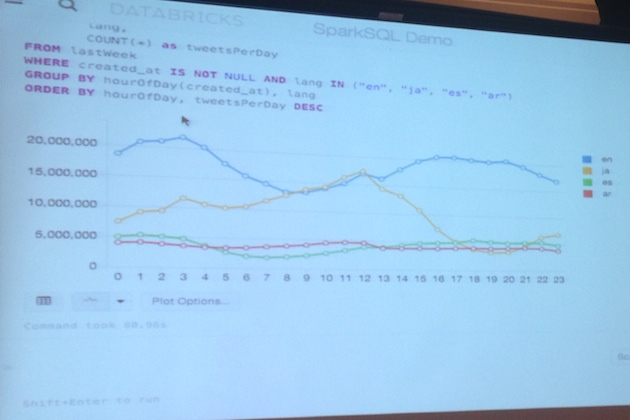
#
Using Spark Streaming for High Velocity Analytics on Cassandra
Albert P Tobey, Tupshin Harper (Datastax)
- “Your house is burning down - 10 minutes ago” - a good example of RT data needs :)
#
Applying the Lambda Architecture with Spark
Jim Scott (MapR Technologies)
Lambda Architecture:
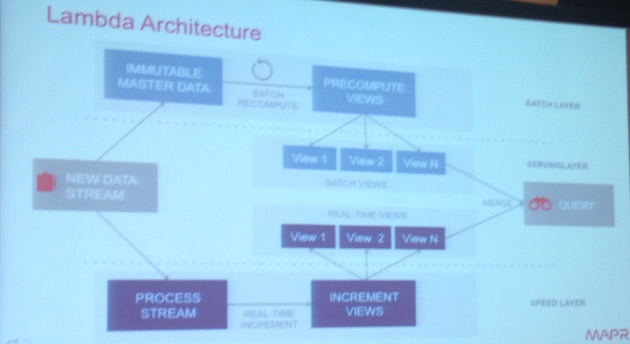
Hadoop: Everyone try to make it solution for everything
You can implement Spark as Lambda Architecture a unified platform
Cisco/MapR implementation of LA. Used to analyze security threats

Spark Stack - use cases of Spark’s usage
#
Testing Spark: Best Practices
Anupama Shetty, Neil Marshall (Ooyala)
Ooyala Application:
Player Events -> Kafka -> Spark Log Processor (batch + stream) -> CDH5/HDFS
Spark Log Processor: Json/Thrift
##
Testing pipeline setup
- Watir for player’s usage simulation
- Kafka+Zookeeper locally (vagrant)
- Spark running on local mode
##
Stress Testing
Gatling: Stress test tool: homepage
- Run performance tests on Jenkins
- Setup baselines for any performance tests w/ different scenarios & users
- Document your hardware so you can have information to tweak this as you need
#
ElasticSpark: Building 1000 node elastic Spark clusters on Amazon Elastic MapReduce
Manjeet Chayel (Amazon Web Services)
Integrated to AWS environment:
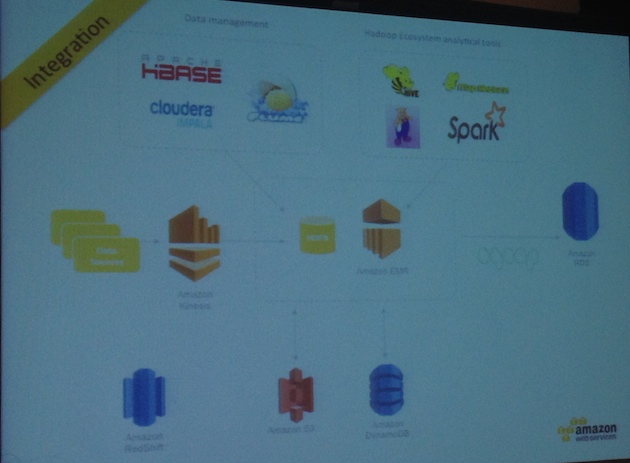
-
Bootstrap actions to install Spark on EMR (currently Spark 0.8 supported)
-
Spark logs are shipped to S3
-
Easy launch, using elastic-mapreduce command line tool

#
Streamlining Search Indexing using Elastic Search and Spark
Holden Karau (Databricks) - @holdenkarau
Source code: Elastic Search on Spark
- Spotting the differences between offline and online indexing are hard
- Writing data to ElasticSearch must use ESOutputFormat for Hadoop and then call
myRDD.saveAsHadoopDataset(jobconf)
#
Easy JSON Data Manipulation in Spark
Yin Huai (Databricks)
Working with JSON are easy:
1- 1 line of code to load the dataset 1- register the dataset as a table
Interface to use here and in the future: sqlContext.jsonRDD(data)
##
Future Work
- Better/Easily handling corrupted data
- JSON column
- SQL DDL commands for defining JSON data sources
- Support for semi-structured such as CSV file
Will be available at Spark 1.0.1
#
StreamSQL on Spark: Manipulating Streams by “SQL” using Spark
Grace(Jie) Huang, Jerry(Saisai) Shao (Intel)
Open-source framework: A Real-Time Analytical Processing (RTAP) example using Spark/Shark
- To manipulate stream data like static data!
- Output of the StreamSQL is a Stream itself!
- Built on top of SparkStreaming + Catalyst

DEMO:


##
Future Work
- Time-based window function
- More generic physical plan design (rule-based)
- Enrich DDL operations. ie:
create stream as table - Support more streaming source (Flume)
- CLI for Catalyst and StreamSQL
#
Spark Job Server: Easy Spark Job Management
Evan Chan, Kelvin Chu (Ooyala, Inc.)
-
Spark Job Server is a vision to provide Spark as a Service internally on Ooyala
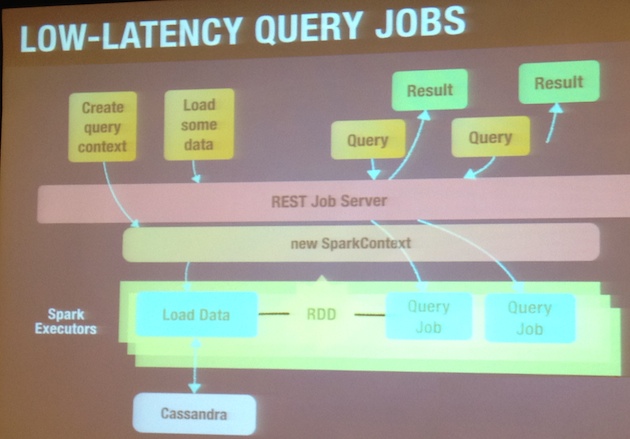
-
Persistence

##
Future Plans
HA and Hot Failover for Jobs
