Spark Summit 2014 - Day 2
Following the Spark Summit 2014 - Day 2
#
The Emergence of the Enterprise Data Hub
Mike Olson (Chief Strategy Officer, Cloudera)
-
Cloudera plans to port Hadoop Ecosystem to Spark, as replacement to M/R.

-
Cloudera will keep support Impala, among Spark components. IMHO, it is split efforts and I can understand why they are doing this, beside biz decision of course!
#
The Future of Spark
Patrick Wendell (Databricks)
##
Goals of project
- Empower Data scientists and engineers to do their job
- Expressive & clean API
- Unified runtime across many environments
- Powerful standard libraries
##
API
- Focus on API stability on Spark 1.0+ (breaking patchs are automatically rejected)
- Minor: Every 3 months (1.1 August), 1.2, 1.3
- Maintenance are kept active 1.0.1, 1.0.2, etc
##
Future is about libraries
- Focus on high-level libraries
- Packaged and distributed w/ Spark to provide full inter-operability
##
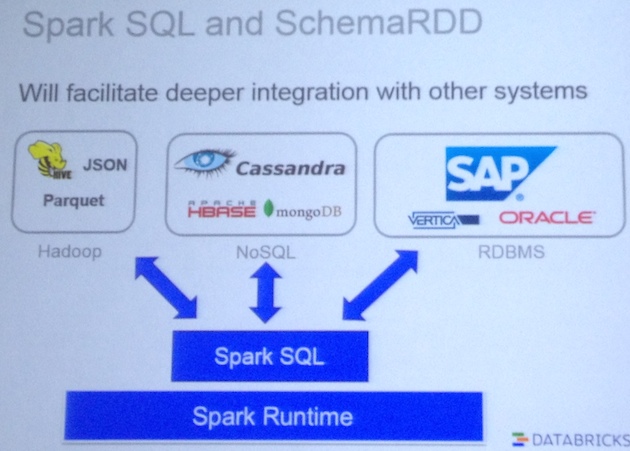
Spark SQL
- More active process
- Notion of schema RDDs
- Focus now are:
- Optimization
- Language extension (towards SQL92)
- Integration
##
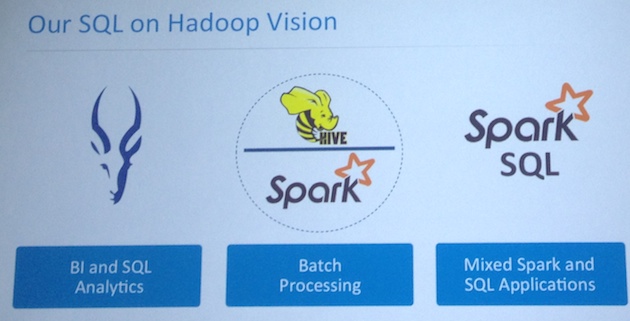
What about Shark?
- Will be replaced by Spark SQL.
- JDBC server component preview on 1.0.1
- Final release to 1.1

##
Spark Core
- Allow extension/innovation by defining internal API’s
- Internal Storage API
- Spark shuffle API (sort-based, pipeline)
##
Timeline
Spark 1.0.1
- JSON Support
Spark 1.1
- Generalized Shuffle Interface
- MLlib stats algorithms
- JDBC Server
- Sort-based shuffle
Spark 1.2
- Refactor Storage Engine
Spark 1.3+
- SparkR
#
Beyond Analytics — Building Data Products for Data Natives
Monica Rogati - @mrogati (VP of Data at Jawbone)
##
Data Natives:
- Beyond digital natives, expect smart and seamlessly adapt
- Expect things to KNOW what they want, ie: Expect the thermostat programs itself
- The promise: better, richer, easier lives
- quite not there yet!

##
Data Products:
Context, Personalization by Using Data, from You, Others and The World
-
How data product can drive life changes (eat, sleep, exercise, achieve your goals)
Data Science is not about charts and Graphs is about delivery better experiences
##
Analytics + Exploration to Build Data Products
- Good Instrumentation
- Reliable Data Flow (fault tolerance, scalable)
- Data Cleanup
- Fast Iteration (if it takes 30min to have a top distro, we not gonna check the data)
- Good UX
More than that:

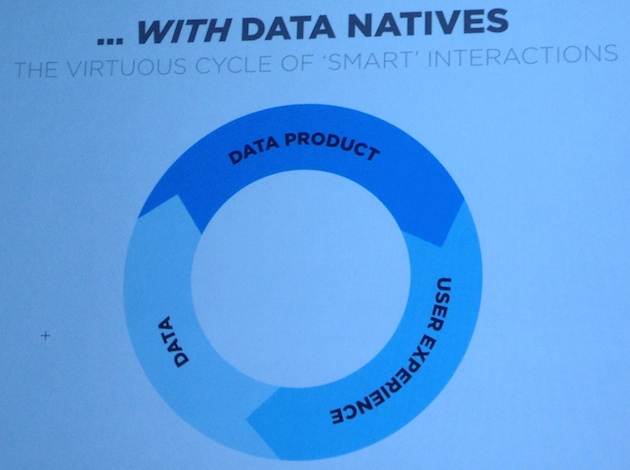
The virtuous cycle of smart interactions:
More & better data comes from better UX, ie: Auto-complete for food app.