Spark Summit 2014 - Day 2 (Afternoon)
Following the Spark Summit 2014 - Day 2
#
BI-style analytics on Spark (without Shark) using SparkSQL & SchemaRDD
Justin Langseth, Farzad Aref (Zoomdata)
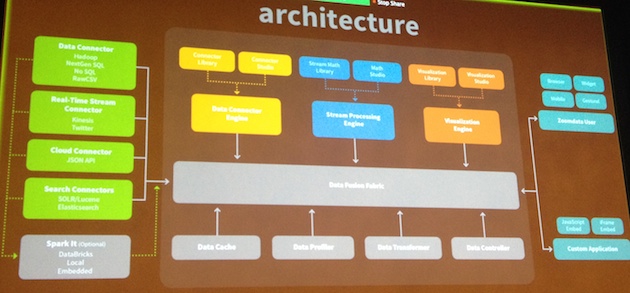
- Moving from Storm to Spark Stream
##
Why they are using Spark?
-
flexible
-
distributed and fast!
-
rich math library (MLlib, graphX, Bagel)
-
Holding small DS
-
Holding aggregation datasets
-
data fusion across disparate sources
-
complex math
##
Challenges
- Sharing Spark contexts
- Sharing RDDs across contexts
- Not sure about Tachyon
#
A Deeper Understanding of Spark Internals
Aaron Davidson (Databricks)
##
Major core components for performance
- exec model
- shuffle
- caching
##
Create exec plan
Pipeline as much as possible Split into stages, on need to reorganize data.
- Single KV must fit in memory!
##
Common issues checklist

##
Tuning the number of partitions

##
Memory problems

#
Spark on YARN: a Deep Dive
Sandy Ryza (Cloudera)
YARN: Execution/Scheduling (decides who/what/WHERE gets to run) ![img] (/images/yarn.jpg)
##
Why to run on YARN?
- manage workloads (allocate shares)
- security (kerberos cluster)
YARN Spark 1.0 + CDH 5.1: Easier app submission spark-submit. Stable since CDH 5.0
##
Yarn Client
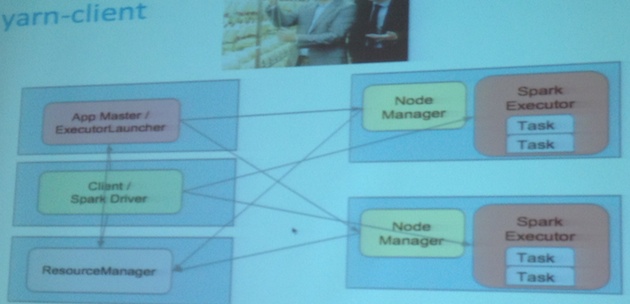
##
Yarn Cluster
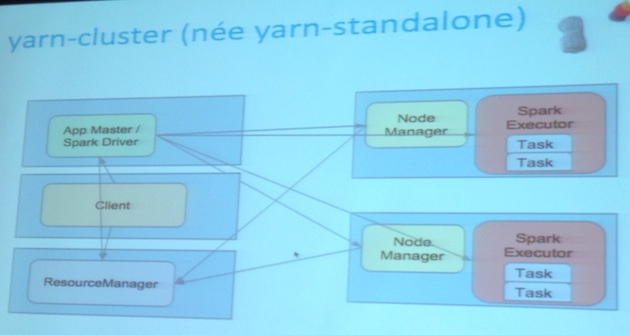
##
Problem with data locality
When running Spark on Yarn, solution is to include on the SparkContext definition where of files location, so yarn can select better containers.
#
Productionizing a 24/7 Spark Streaming service on YARN
Issac Buenrostro, Arup Malakar (Ooyala)
#
Going Live – Things to Address Before Your First Live Deployment
Gary Malouf (MediaCrossing Inc.)
- Spark Standalone would be better if only Spark were running.
- Using MESOS, Chronos for job scheduling
- Cassandra (Long Term Data)
“If you’re starting on 2014, try to go with Spark”
HDFS for small data -> KV data prefer uses Cassandra (rollups, reports, etc)
#
A Web application for interactive data analysis with Spark
Romain Rigaux (Cloudera)
Submitting spark jobs directly
Hue –> Spark Job Server –> Spark
- Leverage on Spark Job Server
Convert your Job to Spark Job Server, using
trait SparkJob
Get started with Spark: deploy Spark Server and compute Pi from your Web Browser