Reading compressed data with Spark using unknown file extensions
This post could also be called Reading .gz.tmp files with Spark. At Socialmetrix we have several pipelines writing logs to AWS S3, sometimes Apache Flume fails on the last phase to rename the final archive from .gz.tmp to .gz, therefore those files are unavailable to be read by SparkContext.textFile API. This post presents our workaround to process those files.
##
Our Problem
The diagram below contains the sink part of our architecture:
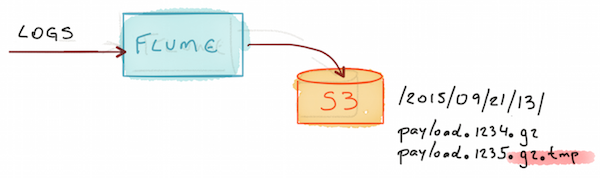
-
Flume is listening to an AMQP queue, dequeuing logs as soon they arrive;
-
Each 10 minutes, Flume Gzip the accumulated content and save to a S3 bucket;
-
For some unknown reason at this moment, some files doesn’t end up with the final desired extension
.gz, instead it is saved with.gz.tmpextension. -
If you try to read this files with Spark (or Hadoop) all you gonna get is gibberish. Because any unknown extension is defaulted to plain-text.
##
Our Workaround
The reason why you can’t read a file .gz.tmp is because Spark try to match the file extension with registered compression codecs and no codec handlers the extension .gz.tmp !!
Having this in mind, the solution is really easy, all we had to do was to extend GzipCodec and override the getDefaultExtension method.
Here is our TmpGzipCodec.scala:
package smx.ananke.spark.util.codecs
import org.apache.hadoop.io.compress.GzipCodec
class TmpGzipCodec extends GzipCodec {
override def getDefaultExtension(): String = ".gz.tmp"
}
Now we just registered this codec, setting spark.hadoop.io.compression.codecs on SparkConf:
val conf = new SparkConf()
// Custom Codec that process .gz.tmp extensions as a common Gzip format
conf.set("spark.hadoop.io.compression.codecs", "smx.ananke.spark.util.codecs.TmpGzipCodec")
val sc = new SparkContext(conf)
val data = sc.textFile("s3n://my-data-bucket/2015/09/21/13/*")
Now it is just a matter of assembly this codec as part of your project, in our case sbt assembly and run your code as usual.
##
Final Note
From the tests we ran on our environment, registering this Codec does not affect Spark’s default configuration, so we still can process extensions .gz, .bz2, etc.