Vagrant + Spark + Zeppelin a toolbox to the Data Analyst (or Data Scientist)
Recently I built an environment to help me to teach Apache Spark, my initial thoughts were to use Docker but I found some issues specially when using older machines, so to avoid more blockers I decided to build a Vagrant image and also complement the package with Apache Zeppelin as UI.
This Vagrant will build on Debian Jessie, with Oracle Java, Apache Spark 1.4.1 and Zeppelin (from the master branch).
##
Getting Started
There are a few steps to build this VM:
1- Follow this instructions to install Vagrant After complete the installation, check your Vagrant version, it is required to be >= 1.5:
$ vagrant version
Installed Version: 1.7.4
Latest Version: 1.7.4
2- Clone this repository:
$ git clone https://github.com/arjones/vagrant-spark-zeppelin.git
3- Run vagrant to build the image:
$ cd vagrant-spark-zeppelin
$ vagrant up
Depending of your internet speed it can take up to 1 hour to build, it takes so long, because there is no binary distribution of Zeppelin and we have to download all dependencies and build it from sources. Be patient, I’m sure you will enjoy the final result.
##
User Interfaces Available
This VM exposes Spark UI (port 4040):
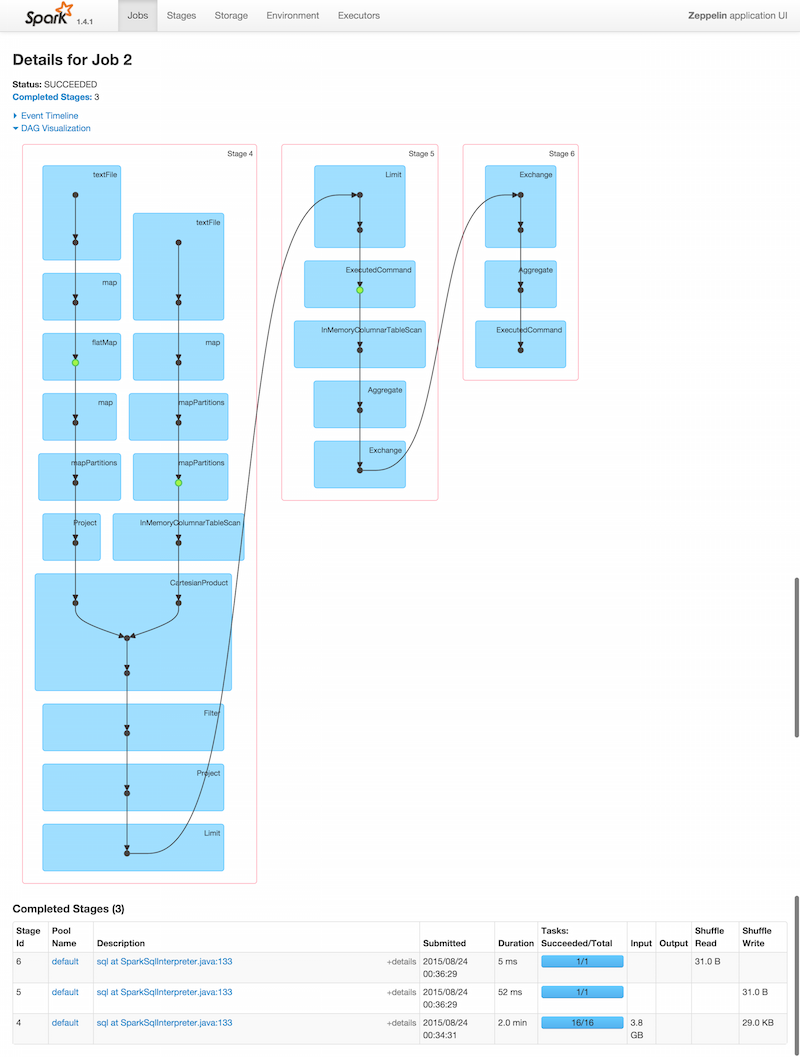
And Zeppelin UI (port 8080), which several screenshots available below:
##
Running examples
When your Vagrant build is finished, you can connect directly to the Zeppelin’s UI and check a few notebooks.
#
Analyzing Access Logs
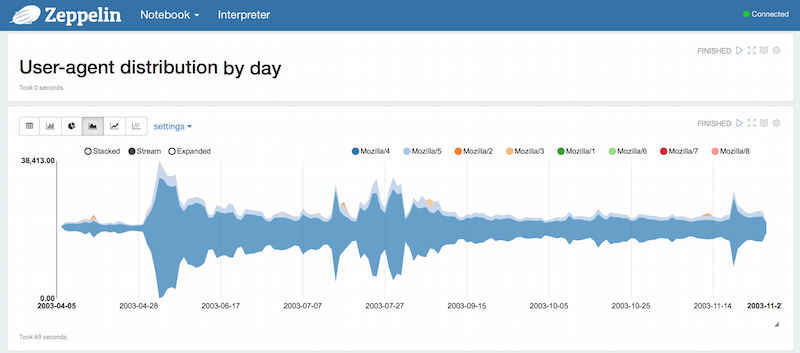
This example uses Spark Core + DataFrames (SparkSQL) to analyze accesslogs (Apache Web Server Logs) released by Andy Baio, I downloaded the original dataset and split it into monthly files, because it increases the parallelism to Spark and also is a more real example. You can have fun creating the same analysis Andy Baio created ;)
#
Consuming Tweets in Realtime with Spark Streaming
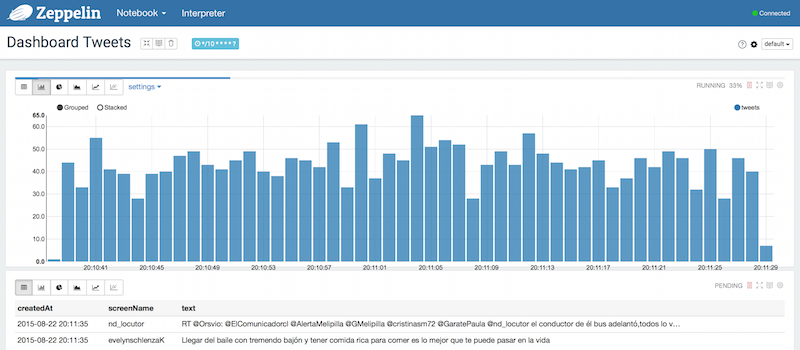
This example is composed of two notebooks, the first connects to Twitter’s stream and the second consumes the RDD and displays the results.
In order to run this sample, you’ll need to have Twitter’s application credentials, you must create your own at http://apps.twitter.com.
##
Create your application:
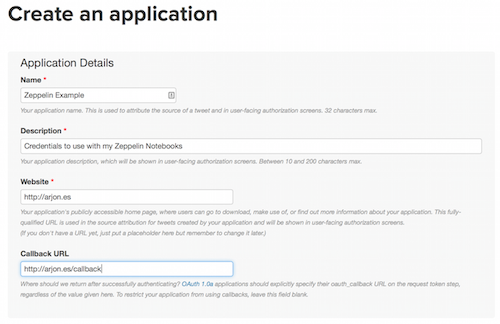
##
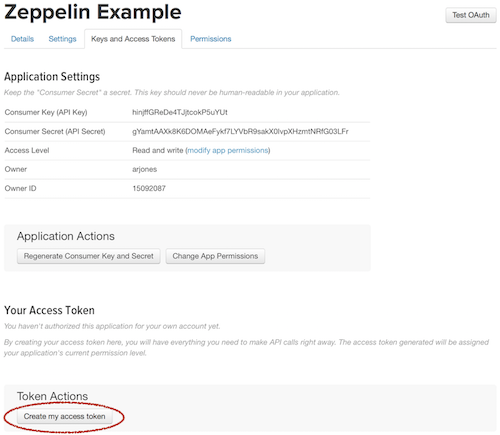
On the tab Keys and Access Tokens press the Create my access token button:
##
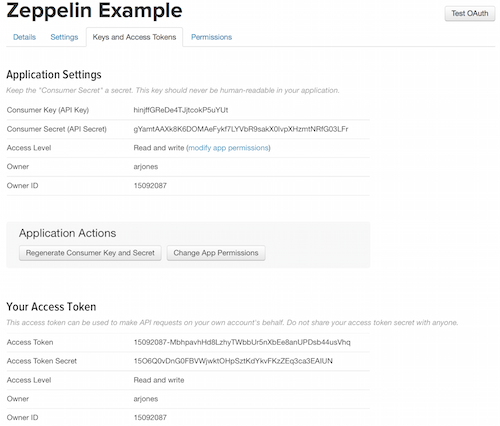
Copy all keys:
##
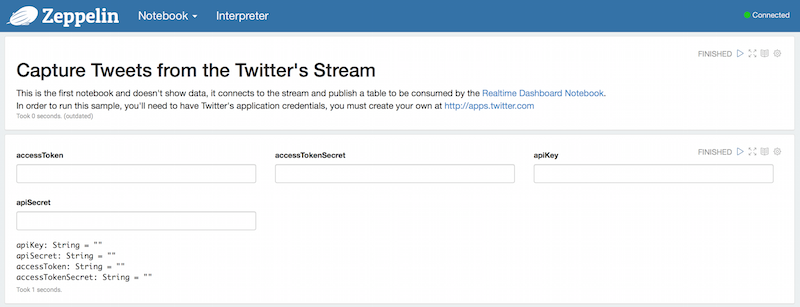
And paste them to the notebook:
#
Troubleshooting
##
Build Problem
A couple of times when I tried to provision Zeppelin, maven failed to build due some dependency that could not be downloaded. You can finish building it manually, just login into the box and run the commands bellow:
$ vagrant ssh
vagrant@debian-jessie:~$ sudo su
root@debian-jessie:/root# cd /usr/zeppelin/
root@debian-jessie:/usr/zeppelin# export MAVEN_VERSION=3.3.1
root@debian-jessie:/usr/zeppelin# export MAVEN_HOME=/usr/apache-maven-$MAVEN_VERSION
root@debian-jessie:/usr/zeppelin# ${MAVEN_HOME}/bin/mvn clean package \
-Pspark-1.4 \
-Dhadoop.version=2.4.0 \
-Phadoop-2.4 -DskipTests
When the build finishes OK you can manually start Zeppelin:
vagrant@debian-jessie:~$ sudo /etc/init.d/zeppelin-daemon.sh start
##
Restarting Streaming/Registering Jars
If you need to restart the streaming context or register new external dependencies (jar files) you will get an error from Zeppelin, AFIK there is no way to reset the context from the UI, so you’ll need to login to the box and restart it:
$ vagrant ssh
vagrant@debian-jessie:~$ sudo /etc/init.d/zeppelin-daemon.sh restart
##
Using Spark-Shell
Zeppelin is really cool for visualizations and to throw some sql and see what happens, but when I have to write more than a few lines of code I miss the autocomplete feature and the speed of a console; that’s where spark-shell comes to rescue.
Login to the box and run spark-shell from the console, the example below also loads to the context some external libraries (joda-time on this sample).
$ vagrant ssh
vagrant@debian-jessie:~$ spark-shell --packages 'joda-time:joda-time:2.8.2,org.joda:joda-convert:1.7'
##
Let’s build a better version together!
I would like to add more notebooks examples but I lack the time to build meaningful ML examples, if you would like to share your notebook or datasets please send me a pull request and let’s build together a better tool for the community!