Data science approach to organizing my playlist
A couple of years ago I created a Spotify’s playlist where I add all tracks I liked, just as the main repository of things I’d like to listen to, no matter the mood I was when I added that song. As time goes, this playlist became less enjoyable to listen due to the change in rhythm - From listen to a Metal song it jumps to Bossa Nova, which is very annoying. This post contains a few data science approaches I applied to organize this playlist and what worked and what didn’t.
#
Obtaining Music Data
I had this idea of organizing this playlist, but didn’t know where to obtain the metadata for the songs, my intuition was I had to extract BPM (Tempo) from each song and organize it. It would be very time consuming because I’d have to download MP3 files and extract meta-data; So the project kept buried for several months.
A few weeks ago I stumble on this post: Can a Data Scientist Replace a DJ? Spotify Manipulation with Python and suddenly I realized all information was already provided by Spotify’s API.
##
Authorization Flow Guide
Follow along using this notebook: obtain-playlist-data.ipynb
- Sign up at Spotify for Developers at https://developer.spotify.com/ and select “Create an app”. Write down your ‘Client ID’ and ‘Client Secret’. While in the “Dashboard”, select the “Edit settings” menu and in the “Redirect URIs” field fill the: http://localhost:7777/callback.
- Export
SPOTIFY_CLIENT_IDandSPOTIFY_CLIENT_SECRET - Open
obtain-playlist-data.ipynband in the Authorization Flow code block, insert your Spotofy’susername. - Execute it. The first time Spotipy will need user authentication and will open a webpage, asking you to log in with your Spotify account and accept the permissions. After doing so, it will redirect you to a link. Copy the ‘Redirect URI’ and paste in the field that will appear in the Notebook. Hit ’enter’.
- Now, you are connected to the Spotify API and capable to get your playlists ID, song IDs and use them to extract the features.
export SPOTIFY_CLIENT_ID=09099999999999999999999999996c7
export SPOTIFY_CLIENT_SECRET=cf9e999999999999999999999999993dcf
git clone https://github.com/arjones/organize-spotify-playlist.git
cd organize-spotify-playlist
# config virtual env
python3 -m venv .venv
source .venv/bin/activate
# install deps
pip install -r requirements.txt
# run notebook
.venv/bin/jupyter notebook
##
Extracting data
Execute notebook, including cell fetch_playlists(sp,username), which will list all your playlists, copy the playlist ID you would like to analyze, mine is 4FO6rgOkMYPlIg8Zt7CK2v. Complete the cell:
playlist_id = '4FO6rgOkMYPlIg8Zt7CK2v'
Run the entire notebook and my-playlist.csv file will be generated. It is the input to test approaches.
#
Evaluating the quality
Because this is not an annotated dataset and if a song is more stimulating than another is a matter of taste, I just randomly checked a few songs to try to get the feeling it is ordered correctly. I know, not very scientific.
#
Exploratory Data Analysis (EDA)
You can follow along the analysis on this notebook.
You can find a complete description of features on the API docs Audio Features, our file contains columns these features:
| Feature | Description |
|---|---|
| acousticness | A confidence measure from 0.0 to 1.0 of whether the track is acoustic. 1.0 represents high confidence the track is acoustic. |
| danceability | Danceability describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable. |
| energy | Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy. |
| instrumentalness | Predicts whether a track contains no vocals. “Ooh” and “aah” sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly “vocal”. The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0. |
| liveness | Detects the presence of an audience in the recording. Higher liveness values represent an increased probability that the track was performed live. A value above 0.8 provides strong likelihood that the track is live. |
| loudness | The overall loudness of a track in decibels (dB). Loudness values are averaged across the entire track and are useful for comparing relative loudness of tracks. Loudness is the quality of a sound that is the primary psychological correlate of physical strength (amplitude). Values typical range between -60 and 0 db. |
| speechiness | Speechiness detects the presence of spoken words in a track. The more exclusively speech-like the recording (e.g. talk show, audio book, poetry), the closer to 1.0 the attribute value. Values above 0.66 describe tracks that are probably made entirely of spoken words. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music. Values below 0.33 most likely represent music and other non-speech-like tracks. |
| tempo | The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration. |
| valence | A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry). |
From intuition, seems danceability, energy, tempo and valence are the most descriptive features to organize a playlist.
Checking this plot is pretty obvious why this playlist is so annoying to listen linearly, metrics are all over the place!
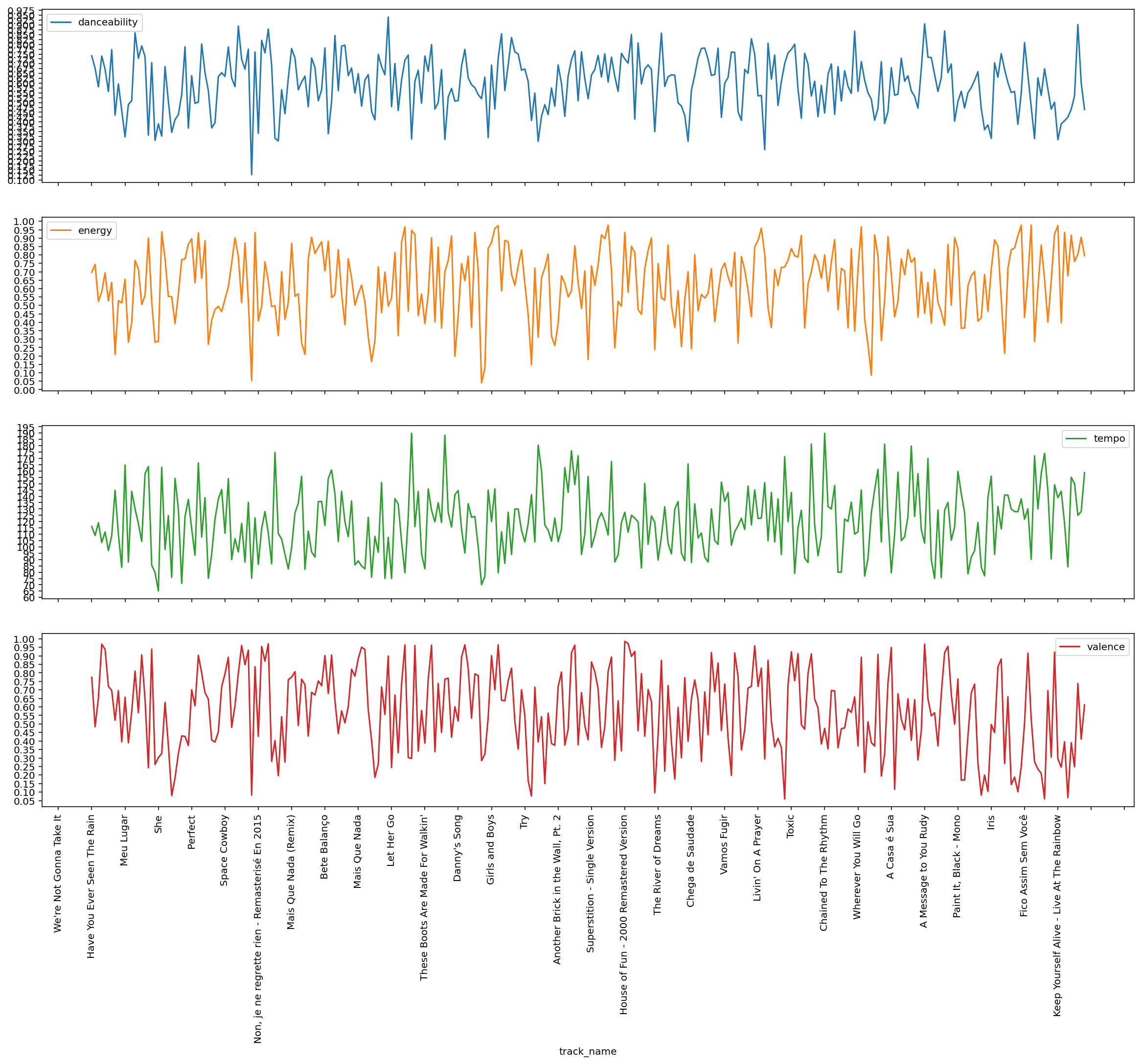
##
Sorting by tempo
tempo
Following my first idea, I simply ordered the whole playlist and to evaluate results, I got a sample of 10 songs and ordered by Tempo:
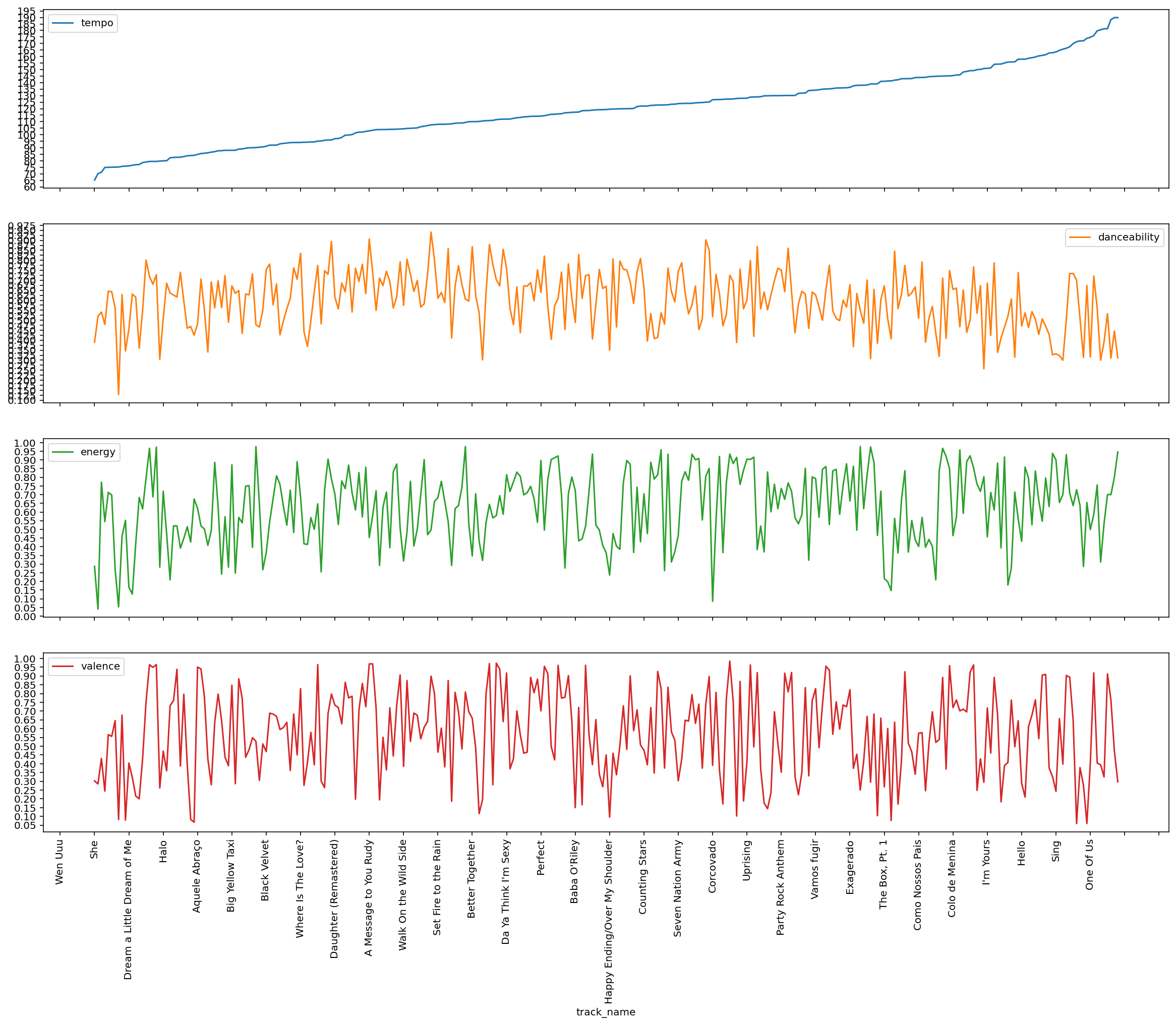
| track_name | url | |
|---|---|---|
| 5 | Human | listen |
| 9 | Skyfall | listen |
| 77 | You Had Me | listen |
| 93 | La Belle De Jour | listen |
| 109 | I Follow Rivers | listen |
| 164 | Cérebro Eletrônico | listen |
| 173 | Wake Me Up - Radio Edit | listen |
| 265 | Don't Stop Me Now - ...Revisited | listen |
| 278 | Paranoid | listen |
| 281 | Meu Lugar | listen |
Although there are a few songs that “landed” on the correct order, this is not the case for most of the songs. For example: Paranoid is stronger than Meu Lugar.
I also tried to sort by energy with much better results:
| track_name | url | |
|---|---|---|
| 5 | Dream a Little Dream of Me | listen |
| 9 | One Note Samba | listen |
| 77 | The Thrill Is Gone | listen |
| 93 | Layla - Acoustic | listen |
| 109 | Skyfall | listen |
| 164 | Have You Ever Seen The Rain | listen |
| 173 | Bete Balanço | listen |
| 265 | Go | listen |
| 278 | Don't Stop Me Now - ...Revisited | listen |
| 281 | Smooth (feat. Rob Thomas) | listen |
I wonder if I can achieve even better results clustering songs together
#
Approach #2 > Clustering
![]()
I took this opportunity to learn a little more about PyCaret, it is an open-source, low-code machine learning library in Python that allows you to go from preparing your data to deploying your model within seconds in your choice of notebook environment.
It has a nice API and removes a lot of boilerplate to do common Machine Learning tasks, such as data preparation, algorithm selection, feature engineering, and model analysis.
Most of the steps I took to cluster the playlist were based on this tutorial: Clustering Tutorial (CLU101) – Level Beginner
Also I recommend reading this post, as it is a comprehensive tutorial to Build and deploy your first machine learning web app
This notebook contains the cluster analysis.
I applied a k-means cluster, applying feature normalization and after applying the elbow score, I’m using n=6. The result isn’t as promising as I expected, it is true clusters contain similar songs as one would expect, but there are strong outliers in the songs.
![]()
###
Cluster 3 songs sample
| track_name | url | |
|---|---|---|
| 288 | 18 and Life | listen |
| 100 | These Boots Are Made For Walkin' | listen |
| 233 | Smiled At Me (Sorriu Para Mim) | listen |
| 118 | Dream A Little Dream Of Me | listen |
| 50 | Non, je ne regrette rien - Remasterisé En 2015 | listen |
| 54 | The Thrill Is Gone | listen |
| 157 | Dona Cila | listen |
| 174 | Telegrama | listen |
| 84 | Dream a Little Dream of Me | listen |
| 9 | Relicário | listen |
| 24 | Skyfall | listen |
| 117 | La vie en rose - Single Version | listen |
| 35 | Aquarela | listen |
| 85 | What a Wonderful World | listen |
| 58 | O bêbado e a equilibrista | listen |
Interactively I tried different clustering modules but got a poor division of clusters, which may indicate we need to add features that would help to better describe separation among songs - I don’t have this information at hand, but would like to add the language of the song as another feature (this playlist contains Portuguese, Spanish, English and French songs).
#
Model constraint solving
![]()
Z3 is a theorem prover from Microsoft Research with support for bitvectors, booleans, arrays, floating-point numbers, strings, and other data types. I recognize it is overkill to the problem but were fun to learn more about this awesome library.
I started to wonder what if I manually classify a sample of songs and then using model constraint solving I could derive values of danceability, energy, tempo and valence, the idea would be like a regression but I don’t care about the value per se, just the order of the songs.
(danceability * 6060.0 + energy * 9770.0) > (danceability * 7110.0 + energy * 9670.0)
and
(danceability * 7110.0 + energy * 9670.0) > (danceability * 9410.0 + energy * 4970.0)
and
(danceability * 5470.0 + energy * 6200.0) > (danceability * 6270.0 + energy * 7520.0)
This approach didn’t work due unsatisfied conditions, likely because my taste on ordering the songs doesn’t comply with a mathematical weight of these variables.
I enjoyed learning about Z3 and remember a few Computer Science classes, so it wasn’t a total waste of time.
Check the z3 notebook here.
#
Conclusion
For now, I could achieve my objectives using simple exploratory data analysis and sorting by Energy, of course the awesome work done by Spotify’s data science team that came up with those scores.
I intend to stress more PyCaret and see how strong it can be on a real project, it is very appealing the speed, easy to use, and deploy this tool put together.
If you are curious, here is the final playlist My Machine Learning Music.